Séries temporais e o InfluxDB
O InfluxDB é um banco utilizado para manipular séries temporais, mas desejo tratar aqui um pouco melhor o conceito de série temporal e a estrutura básica desse banco de dados.
Registros de determinada variável (leia-se conjunto de observações) que representam um período são o que chamamos de série temporal. Muitas vezes armazenamos esses dados em bancos de dados tradicionais (entidade relacionamento), afinal é possível e plausível estruturar esses dados nesse tipo de modelagem.
Em geral, séries temporais se tornam gráficos que representam um determinado período, como por exemplo a quantidade de usuários que acessam um sistema por dia ao longo de um ano, ou ainda um gráfico das despesas mensais de uma empresa na última década. Essas séries de dados que cruzam um período são as séries temporais.
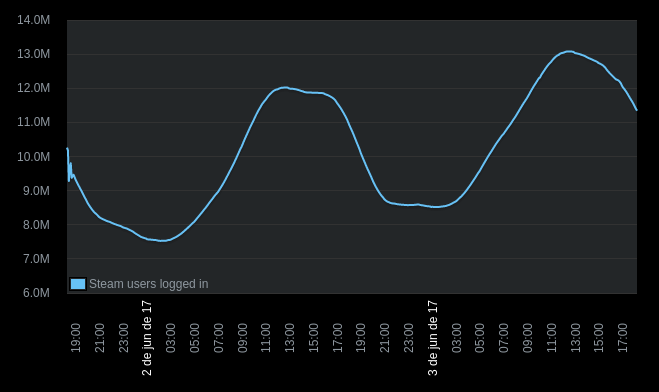
Na imagem acima temos um exemplo de série temporal. Neste gráfico observamos os usuários online na plataforma de games Steam: o eixo y mostra a quantidade de usuários ativos baseado no eixo x que segue uma linha cronológica.
Um critério que vale a atenção é a frequência dos dados. Alguns autores determinam que o período de intervalo entre as observações deve ser constante, mas isso não descaracteriza a série temporal, não completamente. Dados espaçados por intervalos diferentes podem acarretar em alguns problemas do seu modelo final: como representar um gráfico de despesas mensais se faltar um mês? Ou ainda se acumular o valor no mês seguinte? Essa variação pode gerar problemas na hora de interpretar os dados coletados se não for tratado devidamente.
Uma série é composta por 4 tipos te variações: Tendência, Ciclo, Sazonalidade e Variações Irregulares. De toda série é possível extrair essas características, obviamente que cada série expressará de forma distintas cada tipo de variação, algumas dessas características podem ser até nulas (ou neutras).
E o tal do InfluxDB?
O InfluxDB é um banco de dados orientado a séries temporais, ou seja, ele foi projetado e construído pra tratar séries temporais de uma maneira otimizada em performance e modelagem.
Lendo a documentação dos conceitos base do InfluxDB é possível entender melhor as características desse banco. Levantei alguns pontos que para mim foram fundamentais pra compreender a estrutura geral.
Dois pontos iniciais foram importantes para que eu entendesse esse banco de dados:
- Todo registro no banco é obrigatório que se registre a coluna
timecom o conteúdo de uma timestamp. - Existem dois tipos de estruturas que você pode armazenar: Fields (dados) e Tags (“metadados”).
Calma que todo mundo está nervoso. Vamos ver mais informações sobre essa estrutura de banco na sequência.
Fields
Fields representam colunas que você nomeia e armazena dados importantes para a representação da série, funciona no modelo chave-valor. A Field Key é uma string e representa o nome da coluna, consequentemente o Field Value é o valor armazenado.
Não se pode ter um registro sem pelo menos um Field, é obrigatório, trata-se de uma informação básica. No Field você pode gravar dados de todos os tipos, mas o importante é que ele seja um dado que você exibiria num gráfico, cujo único papel é representar uma medição em um instante.
Lembre-se que os Fields não são indexados, isto é, a busca por um Field no banco implica na leitura de todos os valores e, após isso, a sua filtragem: resultando em consultas mais lentas. Ou seja, em bom português, Fields não devem ser dados que precisam de critérios de busca (indexação).
Tags
Tags representam colunas que você nomeia e armazena dados também, no mesmo formato que os Fields: em chave-valor. A característica do dado armazenado deve ser diferente, esse dado é uma espécie de metadado, ele será o alvo das suas consultas no banco: é esse campo aqui que estará no seu WHERE na hora de realizar a sua consulta.
As Tags são indexadas, ou seja, as preferencialmente adotadas como critério de busca. O banco de dados considera elas como opcionais na estrutura de dados, mas se não utiizá-las implicará em busca lentas.
O formato da chave e do valor das Tags são strings, ou seja, quando armazenar alguma informação, mesmo que de caráter numérico, será convertida em string.
Measurement
Measurement é um agrupador de Tags e Fields, ao traçar um paralelo ao modelo de entidade relacionamento, o conceito de Measurement é equivalente ao da tabela. O nome do Measurement representa o valor dos valores que são armazenados nele, tal qual uma tabela.
Série Temporal
Uma série (series) é um conjunto de dados (pontos) resultantes da parametrização das Tags. Isto é, quando realizar uma consulta no Measurement com filtros (condições comparando as Tags), a resultante é uma série temporal.
Database
Database é o mesmo conceito do que o já aplicado e conhecido em bancos SQL tradicionais, ela agrupa as “tabelas”, nesse caso, as Measurements.
Últimos detalhes
O Field time e ao menos mais um outro Field são obrigatórios por serem a base de um banco de dados orientado a séries temporais, afinal o principal objetivo é representar uma série temporal.
Tudo certo então?
Descrevi os conceitos sem trazer muitos exemplos, mas não fique triste comigo. O exemplo na página do InfluxDB é muito ilustrativo, você pode conferir lá esse conteúdo também.
Espero que esse material tenha ajudado a compreender um pouco melhor esse conceito. Qualquer comentário construtivo ou sugestão é muito bem vindo! :)
Bom dia e boa sorte!